Using CCTBX in a Superfacility Workflow¶
Realtime data analysis is a powerful tool, enabling rapid descision making during experiments. Unlike traditional simulation workloads, fast feedback, and automatic data management are central features of this workflow. We therefore use a “superfacility” paradigm to computing, where HPC is a reactive element which is tightly coupled to the experiment’s data processing pipeline. A recent publication demonstrates these workflows at NERSC. Fast feedback (usually in the form of partial or even complete data analysis within minutes of a completed experimental trial) is vital to steer experiments where instrument time is limited. Hence experiments are adopting a strategy of integrating HPC facilities into their data processing pipelines in order to make use of their computational resources. Here we demonstrate how this workflow was deployed at multiple sites: data was collected at the LCLS and analyzed at NERSC, OLCF, and ALCF.
The following figure outlines the LCLS + NERSC workflow.
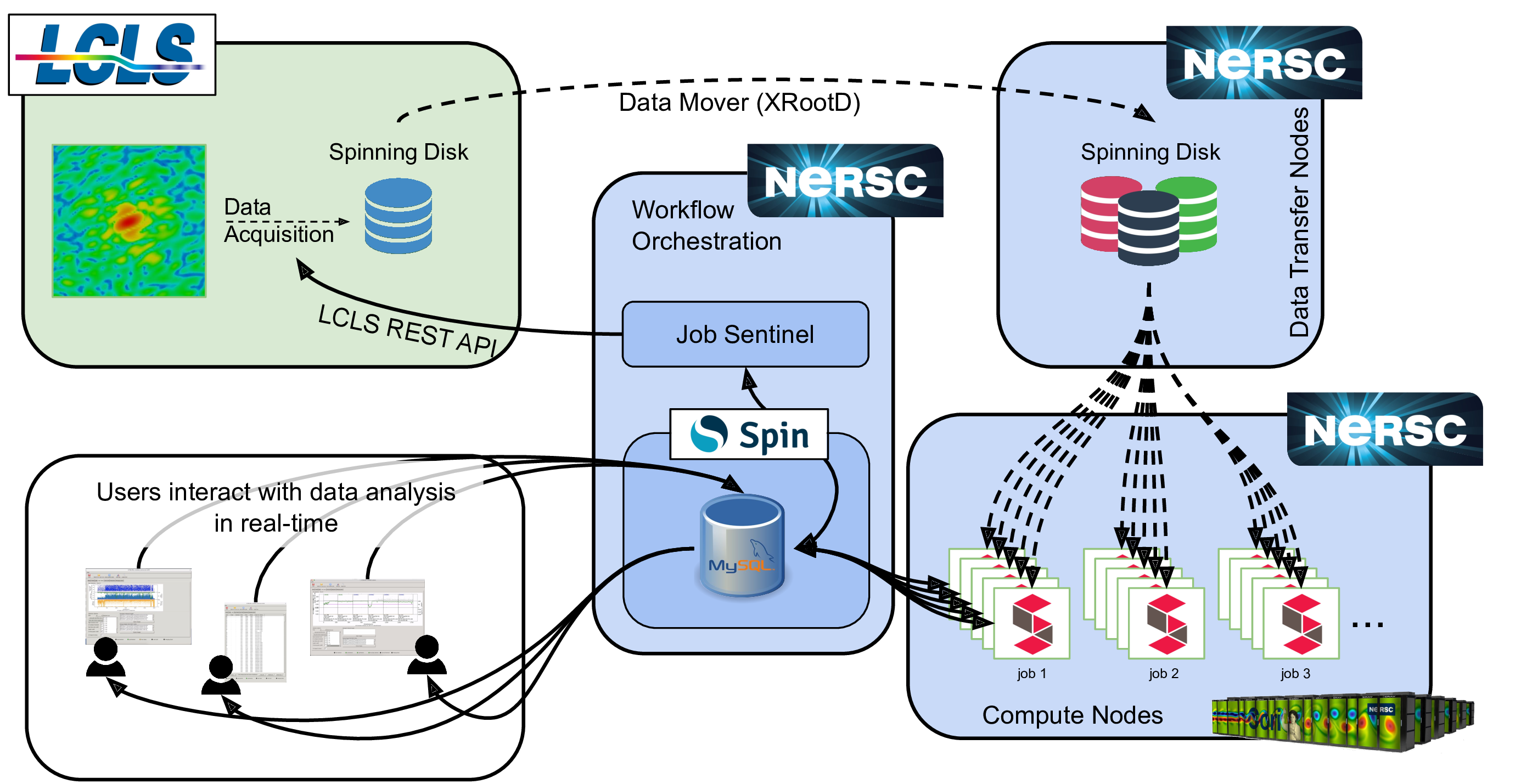
Example of the NERSC-LCLS Superfacility workflow. Data is collected at LCLS (upper left, green, box) where it is stored on disk. Once an experimental run is completed, a XRootD cluster automatically copies all files associated with that run to the SCRATCH Lustre file system at NERSC (dashed arrow) over the ESNet network, using two data transfer nodes. Once the data for a run has been completely transferred to NERSC, the CCTBX “job sentinel” tool (running on a login node, middle box) automatically submits data analysis jobs (running in shifter containers, bottom right box). The data analysis at NERSC are coordinated by a MySQL database hosted on the Spin microservices platform (center box). The job sentinel makes the determination to submit new jobs by comparing the parameters stored in the database with the list of completed runs using the the LCLS REST API.¶
CCTBX¶
Data was analyzed using the Computational Crystallographic Toolbox (CCTBX). CCTBX is a software framework to perform serial crystallographic data analysis on high-performance computing systems. Data analysis involves processing anywhere between hundreds of thousands to millions of images. These are stored as arrays of pixel intensity values. Here we focus on a subset of features and algorithms – called cctbx.xfel – which specialize in SFX experimental data analysis. The result of data processing is a list of features (such a Bragg spot intensity and shape, and Miller indices) derived from the input data set, as well as refined experimental parameters (such as detector position and orientation relative to the beam).
cctbx.xfel is a python package which is designed to interface with other SFX data analysis workflows, such as DAILS. This makes it highly versatile, and allows non-software specialists to implement data analysis algorithms. Furthermore, most experimental facilities provide custom software packages to interface with facility data collection and logging. These packages almost always provide a Python API. Therefore the data analysis coordinated and scripted using Python
The computationally intensive work is implemented in C++, and recent work makes use of CUDA and Kokkos for some of the most computationally expensive algorithms. cctbx.xfel makes use of a producer/consumer model to distribute parallel work over MPI ranks. openMP is enabled for single-rank parallelism.
Pipeline Management¶
Important
XFEL data analysis requires interactive pipeline management tools in order to automate routine tasks (such as organizing files, and job dependencies) and effectively provide fast feedback to experiment operators.
cctbx.xfel provides a complete pipeline management systems in the form of a graphical user interface. Either by monitoring a directory for new data, or by using the experimental facility’s API (if one exists) cctbx.xfel automatically detects new data (grouped into “runs”). The user can choose to tag these experimental runs with scientifically-relevant tags, similar to a log book. Runs are grouped into “trials”, which share the same parameters for data analysis. cctbx.xfel automatically detects unprocessed trials (either because new data has come in, or the user submitted new data analysis parameters), and submits new job scripts. As the data processing jobs run, they report the status of the data analysis in real time to a central mySQL data base. This allows scientists to follow the complete data analysis from start to finish, and make rapid decisions about their experiments.
cctbx.xfel can compose and submit jobscripts for a variety of job schedulers (Slurm, PBS, LFS, and SGE) and CCTBX parameter files. By comparing available data, user inputs, and the list of completed jobs (from the mySQL database described below) new jobs can be automatically submitted. E.g. when new data files have finished transferring, or if the users modify the analysis parameters. Once data analysis parameters have been broadcast to all MPI ranks, data processing occurs independently for each image until the final step. Since each image can be very different (and often doesn’t contain the same features), the per-image data processing time can vary vastly. Hence, in order to remain load-balanced between MPI ranks, we employ producer/consumer parallelism.
In order to coordinate data analysis among different users and Slurm jobs, each cctbx.xfel instance running on the compute nodes connects to a MySQL database, and “reports” the images it is analyzing together with analysis parameters and outcomes (e.g. successful spot finding). This allows instant feedback on the outcomes of the data analysis amongst many users at once. Therefore the database needs to be able to accept potentially thousands of connections at once. We find that a MySQL database instance hosted on NERSC’s “Spin” micro-services platform is capable of accommodating the required rate of database transactions. In past experiments, we observed a peak peak of approx 8000 commit transactions per second, which Spin is capable of accommodating.
Cross-Facility Communication¶
For experiments conducted at the LCLS light source, we use psana to access raw data and orchestrate parallel I/O. The LCLS provides a REST API which exposes the state of an experimental run (and data transfer) to external facilities. A run can be in one of the following states
The run is ongoing and data is still being collected into xtc “streams”.
The run is completed and data is being transferred.
The run is completed and data has been transferred to NERSC.
cctbx.xfel monitors this API from NERSC or from LCLS. If it is running at LCLS, then it can commence with data analysis when the API returns state 2. If it is running at NERSC, then data the GUI presents the run for analysis only once the API returns state 3.
Data is transferred between sites using XRootD and Globus (cf the section on Data Transfer). It is essential that this process be automated, allowing scientists to focus on running the experiment, and data analysis. Furthermore it is essential that data is transferred at the highest possible speed, with a typical LCLS experiment producing approx. 15 TB duing a 12-hour shift. We therefore make use of the ESNet network. Furthermore XRootD and Globus make use of concurrent data transfers and data transfer nodes.
Facility Requirements¶
Important
This workflow has many moving parts, all of which need to work well (and well together) to allow of real-time data processing.
When running at on a supercomputer, this workflow requires three types of resources: computational resources; workflow orchestration; and data handling.
Computational Resources:¶
Many (64 and more) compute nodes run the computationally-intensive data analysis tasks (image processing and data reduction). Future data analysis algorithms will also require GPU-accelerated compute nodes.
Workflow Orchestration:¶
Workflow orchestration requires that a persistent state is kept between individual compute jobs. CCTBX stores this state in a MySQL database which stores a record of completed and new work, as well as workflow statistics. This is fairly light weight (producing approx. 100 GB in a 12 hour shift). It does need to be scalable and have a fast network connection to the compute nodes (8000 commit transactions per second are common).
Furthermore cctbx.xfel the GUI which is used by the science teams to monitor the data analysis needs to be run on a node that is capable of accessing both the mySQL database, and the job scheduler. For that reason, this is usually hosted on a workflow node, or a login node.
Data handling:¶
Incoming data is frequently handled by dedicated fata transfer nodes that are optimized to ingest large amounts of data from an external source. Furthermore the Facility requires high-performance file systems that can accommodate high-speed concurrent reads. For high-speed concurrent writes, CCTBX uses burst buffers (at NERSC, or at OLCF), or temporary on-node storage (eg. Xfs at NERSC)
Portability¶
Here we outline our efforts to make the cctbx.xfel* workflow portable accross ALCF, NERSC, and OLCF. Portability requires that the data movement, data analysis, and workflow orchstration components be independent of the HPC environment where data processing takes place. While some amount of site-specific customization in the workflow’s setup is inevitable, we improved portability by employing the following technologies:
Enable data to be “sent everywhere” at short notice.
Build protable containers for the data analysis software. This allows rapdid re-deployment at a new site.
Host workflow orchestration on Kubernetes-based microservices platforms. This minimizes the amount of custom (site-local) pipeline management code.
The portability of the diffent cctbx.xfel workflow components NERSC, OLCF, ALCF, and LCLS is summarized in the following table.
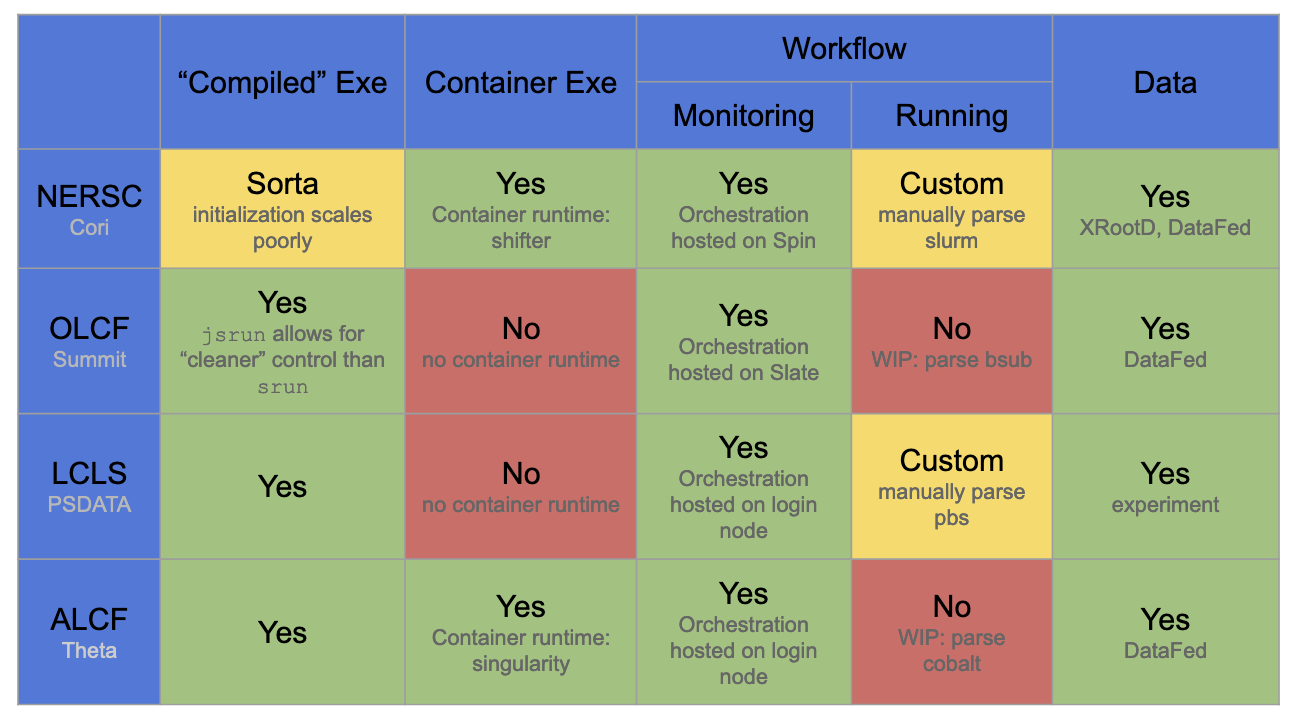
Portability experiences of the CCTBX Superfacility workflow accross 4 facilties: NERSC, OLCF, ALCF, and LCLS. Green tiles indicate workflow components that perform well without significant site-specific customization (e.g. writing new code). Yellow tiles indicate components that while technically portable required significant size-specific code to be added to cctbx.xfel. Red tiles indicate components that are currently not portable.¶
Data Movement¶
XRootD was used for data transfers between NERSC and LCLS. While this setup allowed for scalable high-performance data transfers between LCLS and NERSC, it relied on an explicit pairing between LCLS and NERSC. Redirecting data transfers to another site (eg. ALCF or OLCF) would therefore require setting up a new XRootD cluster at the target site, and reconfigurign the cluter at LCLS.
This project therefore explored the solutions that would enable the endpoint for data transfers to be changed quickly – ideally with as little reconfiguration of the pipeline as possible. To this end we explored DataFed as it is built on Globus. Globus is availabe at all ASCR HPC sites, and has been configured for performance and high-concurrency. Using Globus as the data-plane therefore allows us to automatically make use of site-specific optimizations. DataFed is appealing to the cctbx.xfel workflow as it provides a cohesive data managament ecosystem which works well with the data lifecycle of Beamline workflows.
Use Portable Containers¶
We where able to build constainers that run on Shifter and Signularity, without needing to rebuild the image. Crucial to building a portable CCTBX container is including and ABI-compatible MPICH in the image, as well as enabling the dynamic linker to find system libraries.
MPI¶
Shifter automatically links MPI into the image https://docs.nersc.gov/development/shifter/how-to-use/#using-mpi-in-shifter. Therefore, a standard MPICH (and if needed mpi4py) install such this dockerfile
FROM ubuntu:latest
WORKDIR /opt
RUN \
apt-get update && \
apt-get install --yes \
build-essential \
gfortran \
python3-dev \
python3-pip \
wget && \
apt-get clean all
ARG mpich=3.3
ARG mpich_prefix=mpich-$mpich
RUN \
wget https://www.mpich.org/static/downloads/$mpich/$mpich_prefix.tar.gz && \
tar xvzf $mpich_prefix.tar.gz && \
cd $mpich_prefix && \
./configure && \
make -j 4 && \
make install && \
make clean && \
cd .. && \
rm -rf $mpich_prefix
RUN /sbin/ldconfig
RUN python3 -m pip install mpi4py
will allow the dynamic linker to link against the system’s MPICH at runtime.
Shifter achieves this by mounting NERSC-specific libraries in the image and
automatically prepending this location to LD_LIBRARY_PATH. ALCF’s
Singularity runtime instead will only prepend the contents of
SINGULARITYENV_LD_LIBRARY_PATH.
Linking External libraries¶
In order to allow containers to resolve system-specific libraries at runtime,
some care needs to taken when building containers. First, the recipe in the
section on MPI (above) ensures that mpi4py is linked against an
ABI-compatible MPICH by building MPICH and using pip to build mpi4py (instead of
using apt and anaconda). This also avoids the use of RPATH`s, which can
overwrite the :code:`LD_LIBRARY_PATH. Second sometimes a the executing
environment needs to be able to prepend paths into the LD_LIBRARY_PATH
(to overwrite libraries therin). An example of this is used here:
https://www.alcf.anl.gov/support-center/theta/singularity-theta for ALCF
Theta:
# Use Cray's Application Binary Independent MPI build
module swap cray-mpich cray-mpich-abi
# include CRAY_LD_LIBRARY_PATH in to the system library path
export LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH
# also need this additional library
export LD_LIBRARY_PATH=/opt/cray/wlm_detect/default/lib64/:$LD_LIBRARY_PATH
# in order to pass environment variables to a Singularity container create the variable
# with the SINGULARITYENV_ prefix
export SINGULARITYENV_LD_LIBRARY_PATH=$LD_LIBRARY_PATH
CCTBX exposes a similar variable DOCKER_LD_LIBRARY_PATH_PRE by including
export LD_LIBRARY_PATH=$DOCKER_LD_LIBRARY_PATH_PRE:$LD_LIBRARY_PATH in
its entrypoint.sh. We find that controling the linker’s behaviour by
mounting system libraries and modifying the LD_LIBRARY_PATH is
sufficient in building a portable CCTBX image.
Workflow Orchestration and Microservices¶
CCTBX was already making use of Microservices to host part of its workflow orchstration, by hosting the mySQL database on NERSC’s Spin. It was therefore relatively easy to port the Rancher setup for the database to OLCF’s Slate platform. Slate has an additional capability over Spin: it can access the Summit queue. We therefore deployed a noVNC container on Slate. The openshift deployment can be found here: https://github.com/CrossFacilityWorkflows/BestPractices/tree/main/examples/novnc This workload is capable of hosting the cctbx.xfel GUI. This way the entire cctbx.xfel workflow orchestration component is hosted on the same microservices platform.